Nim is presented as an imperative language. And yes, it has some of its roots in the Pascal line of languages, but it also has a set of powerful abstraction mechanisms making it very suitable for object oriented programming. And when I write “object oriented” I am referring to a broader flexible sense of OO in which objects can be formulated with attached behavior, polymorphism between different objects, some kind of reuse model of code (inheritance etc) and some type of dynamic dispatch.
Since I am a long time Smalltalker that is my main reference for “good OO” and not the … monstrous OO often seen in Java or C++. Its hard to explain the differences, but let me just say that OO in Smalltalk is elegant and natural, very much like in Ruby or Python - but ever so more streamlined. Smalltalk is a dynamically strongly typed reflective language with a heavily closure based style.
In this article I will try to make “sense” out of how to do OO in Nim.
OO in Smalltalk Link to heading
We roughly have the following mechanisms in Smalltalk related to OO, and the first 4 are the same as in Java:
- Single inheritance class model.
- Normal "receiver only" dynamic dispatch.
- Able to do super and self calls.
- Garbage collection.
In addition Smalltalk adds very important salt and pepper, which Java definitely doesn't have:
- Everything is an object including all datatypes, so we can inherit from them and also extend/override with methods.
- Every behavior is a message invoking a method, including all operators. Only exceptions are assignment and return.
- Dynamic duck typing.
- Pervasive use of closures with support of non local return enabling expressive protocols.
Then of course Smalltalk goes "OO Banzai!" with:
- Classes are objects too, so they have methods and inheritance and a class...
- Class variables and class instance variables.
- Full meta level meaning your code can modify itself 100% during runtime.
For doing reasonable OO the Banzai stuff is not needed, its however what enables Smalltalk to be a fully reflective IDE in itself. Bullets 5-9 are also not essential to reasonable OO, but they are what makes Smalltalk transcend languages like Java, so in that sense its interesting to see what Nim offers in the similar space.
So ideally I want to see Nim support at least 1-4 and hopefully also cover 5-8 but using other mechanisms, given that Nim is a totally different beast.
How does Nim stack up? Link to heading
Learning Nim is really fun, its like a “box of chocolate” with lots of slick mechanisms to learn. This also makes it slightly confusing - what stuff should I use regularly? What should I avoid? What parts combine to enable OO in Nim? Its not clear :)
And this walk through is also not entirely clear, but its a series of experiments with concluding remarks referring back to the Smalltalk laundry list above. Could I restructure this article? Probably. Did I use too much sample code? Probably. Is the article too long? No doubt.
But here we go…
Procs Link to heading
We can start with the work horse in Nim - procs . A proc is simply a regular statically typed function. This means we have static compile time binding for them - and they support “overloading” on the arguments, so we can define many procs with different implementations for different types on the arguments.
Also, Nim introduced so called UFCS before D established that acronym, so syntactically these calls are equivalent:
fn(a, b)
a.fn(b)
Having both proc overloading and the Uniform Function Call Syntax in combination with the neat modules system where one module can define procs using types from other modules (pretty obvious you can do that) - then we already can do “OO looking code” in a simpler fashion. For example we can easily add a reversed() method to the type string that returns a new string with characters reversed.
First, lets just verify that string doesn’t already have it. I use Aporia and I have turned on “Enable suggest feature” in Preferences, then it tries to help me:
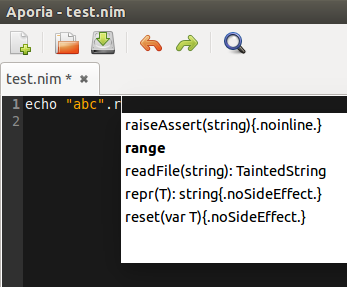
…so nothing there right now. Let’s hack. In the beginning below we see that reversed() already exists for openarray, which means both array and seq types. Then we add it for string:
# Some data to play with
var anArray = [1, 2, 3, 4]
var aSequence = @["a", "b", "c"]
# Aha, in module algorithm.nim we already have reversed() for openarray
# which is the type covering both array and seq.
# Hehe, we can import down here too if we like
import algorithm
# And yes, reversed works for those guys
echo(anArray.reversed())
echo(aSequence.reversed())
# But it doesn't work for string, let's add it
proc reversed(s: string) :string =
## Shamefully ripped from algorithm.nim for openarrays
result = s
var x = 0
var y = s.high
while x < y:
swap(result[x], result[y])
dec(y)
inc(x)
# Testing it, works for literals
echo "abc".reversed
# Works for vars too of course :)
var test = "Goran"
echo(test)
echo(test.reversed)
# And yes, not destructive. "reverse" (no d) would be destructive.
echo(test)
…using Aporia we can actually immediately see right after we wrote that proc, that the compiler picked it up and offered it as a suggestion when we started typing in test code:
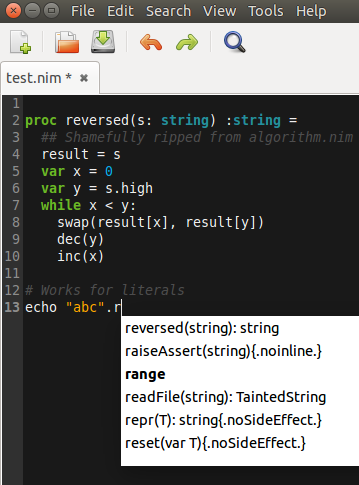
Compile and run:
gokr@yoda:~$ nim c -r --verbosity:0 testreversed.nim
@[4, 3, 2, 1]
@[c, b, a]
cba
Goran
naroG
Goran
gokr@yoda:~$
Funny sidenote: “Göran” didn’t work so well… UTF8 strikes! But this is fully natural given our non-UTF8 aware implementation, we end up reversing the two UTF8 bytes representing “ö”…
Remark Link to heading
In each “Remark” heading I try to connect back to Smalltalk and that laundry list. Most Smalltalk implementations have some mechanism for “class extensions” (able to add methods in classes outside your package) and they are quite easy in Nim, even for builtin datatypes, since both procs (and methods, continue reading) are defined separately and operate on types, not “just” objects. And we have the UFCS syntactic sugaring, making the illusion complete.
In Nim most operators are handled the same way, so we can implement things that are “hard wired” in other languages, like == (equality) using the same mechanism. This nicely reverbs with Smalltalk.
I would say that 5 and 6 on that list have fair support in Nim.
Distinct types Link to heading
One extra twist regarding the fundamental datatypes in Nim is that we can do type aliases and distinct types of them. An alias is just that - same, same. But a distinct type creates a completely separate type - it just happens to “be” the same thing. This makes the builtin datatypes a bit more malleable and also enables our code to be very typesafe and strict.
Play time, just messing a bit:
# We create a FreakInt which behaves like an int, but is its own type.
# We can not pass a FreakInt when someone wants an int - and vice versa.
# This also means that all operators and procs defined for ints, do NOT
# apply for a FreakInt - they are dumb as hell basically.
type
FreakInt = distinct int
# Ok, so we borrow multiplication by an int
proc `*` (x: FreakInt, y: int): FreakInt {.borrow.}
# Let's override `+`: FreakInt also multiplies by 2...
proc `+` (x, y: FreakInt): FreakInt =
FreakInt((int(x) + int(y)) * 2)
# Can we go down the rabbit hole? What happens with a distinct
# type of a distinct type?
type
UltraFreak = distinct FreakInt
# Ok, so we borrow `*` and `+` from FreakInt?
# No, it turns out it borrows from the base type int - this is NOT inheritance.
proc `+` (x, y: UltraFreak): UltraFreak {.borrow.}
proc `*` (x: UltraFreak, y: int): UltraFreak {.borrow.}
# UltraFreak ints multiply by 10 when doing subtraction...
proc `-` (x, y: UltraFreak): UltraFreak =
UltraFreak((int(x) - int(y)) * 10)
# Hold onto hat..
var
i: int = 5
f: FreakInt = 6.FreakInt # Conversion, same as FreakInt(6)
u: UltraFreak = 7.UltraFreak
# Did FreakInt manage to borrow `*` from int? yes
assert(int(f * i) == 30)
# Did FreakInt manage to override `+`? yes
assert(int(f + f) == 24)
# Did UltraFreak manage to borrow `+` from... what?
# Ok, from int, not FreakInt!
assert(int(u + u) == 14)
# Also from int, not FreakInt!
assert(int(u * i) == 35)
# But we did get our own `-`, right? Yes we did.
assert(int(u - 3.UltraFreak) == 40)
Remark Link to heading
It seems to me that distinct types in Nim captures even more of 5 and 6 - while we can’t inherit from fundamental datatypes, we can in fact:
- Create distinct types from them and extend those.
- And actually even borrow base type implementations on a proc-by-proc or op-by-op basis. But ONLY from the base type. I guess this also works for other base types than the builtins.
There is quite a lot of other mechanisms that I will not cover here, like overriding “."-access or the dereferencing operator “[]” and so on. I would say all of this is enough in order to be able to work with fundamental types in “an object oriented manner” similar to how we can do it in Smalltalk.
Tuples Link to heading
Ok, let’s move to more complex data. A tuple is like a struct in C or a “record” or a “row” in a database table. Its a composition of named and typed fields in a specific order:
type
Person: tuple[name: string, age: int]
So its the simplest heterogenous composition of data in Nim, there is no overhead at all and they do not know their type at runtime (so dynamic dispatch on tuples is not possible) and there is no hiding of members either.
Thus a tuple is a very basic type, and given their limitations compared to their Bigger Brother the object, they should be used when convenience and/or zero overhead matters more than information hiding or complex attached behavior.
In the Nim standard library we find tuples as the smaller building blocks inside Collection types like KeyValuePair, a Complex number, a Point or a Rectangle in graphics, or a Name & Version combination etc. Small and simple things, and when it comes to Collections the fact that they carry zero storage overhead is of course important. But they are not used even nearly as much as objects are, some quick searches like grep -r "= tuple" in lib shows 25 hits, objects are used typically 10x more, and I probably listed half of the tuple uses in the first sentence of this paragraph :)
If you are unsure if you should use a tuple or an object, I suspect you are better off with an object.
Remark Link to heading
Tuples are seemingly most interesting internally in Collections or similar lower level code. For most OO code objects are to be preferred.
Ref and ptr Link to heading
Before we go further we need to look at ref and ptr in Nim. Nim can work closer to the metal than say Java or Smalltalk. To be able to do that, Nim needs regular C style pointers, they are declared as ptr Sometype. Such a pointer variable, that directly points to a memory location, is normally used when interfacing with C or when you want to play slightly “outside the box”, for example if you wish to allocate something in memory and pass it over to another thread - keeping track yourself when to deallocate.
As a language that wants to cover all bases this is essential stuff to have, and of course - this is unsafe territory, feel free to shoot yourself in your proverbial foot. But for regular “application level” code we probably do not need to use ptrat all.
Instead we use ref which is in fact also a pointer, but its a friendlier one that does a bit of automatic allocation and especially deallocation for us using the garbage collector. If we declare type KeyValuePair = tuple[key: string, value: string] without using ref - and then use that to declare a variable x in a proc, then that variable will be allocated in the stack frame when the proc is called, and thus also disappear when the proc returns. Its fairly logical - var x is a tuple, not a pointer to one. Nothing is in this case allocated on the heap and no garbage collection is needed, since the whole value was inside the stack frame.
But for making data that lives longer than the current invocation of a proc, we tend to use “ref” types. For such types the value will be allocated on the heap, and the variable will hold a pointer to it, and the garbage collector tracks our references.
A bit of training code showing that while we normally use ref to refer to objects, we can refer to other types like enums as well:
# Playing with ref, enum and assignment
type
LightImpl = enum LiGreen, LiYellow, LiRed
Light = ref LightImpl
# Convenience method, good style
proc newLight(): Light = new(result)
var
# This is a variable allocated in the stackframe
light: LightImpl
# This allocates and initializes a LightImpl on the heap
# and makes lightHolder refer to it. If you do initialization
# separately you can also use `new(lightHolder)`
lightHolder = new(LightImpl)
# Better style to call a proc to do it.
lightHolder2 = newLight()
# Dereference to get the Light value, check it has the default value
assert(lightHolder[] == LiGreen)
# Set the local stackframe allocated Light to a different value
light = LiYellow
# Assignment copies the bits of light to the Light on the heap
# You need to use `[]` dereferencing here.
lightHolder[] = light
# Should be yellow now
assert(lightHolder[] == LiYellow)
# Let's modify the local stackframe light
light = LiRed
# Make sure the Light on the heap is still yellow
assert(lightHolder[] == LiYellow)
Remark Link to heading
Since I have been working primarily in Java, C# and Smalltalk the last 20 years (ouch) I have gotten used to variables almost always being references
to objects, and objects almost always being allocated on the heap. Nim has value types
, and then ref and ptr is used to create reference types pointing at them. I am not a language designer though - perhaps one can express it using more precise words.
Proc variables are automatically allocated in the stack frame, as usual. This is also true of ref variables, but for those we only allocate the actual pointer bits there. But where does it point? This is where an allocation step comes into play - using new(). Calling new() with a ref variable as argument, will allocate the type that the ref variable refers to on the heap, and then set our ref variable to point there. Obviously you can also explicitly pass the type that the ref refers to (in the example code LightImpl) but that makes the code more brittle and less encapsulated.
I think the greater flexibility of Nim, where we can choose to allocate values or references to values has benefits in more complex scenarios - and definitely for performance. It seems fairly well “embedded” in nice mechanisms so that general application level OO code doesn’t suffer too much from this “complication”.
Objects Link to heading
Ah, finally! But this is not your dad’s Java objects, or your granddad’s Smalltalk objects. First of all, we don’t have “classes” - in Nim that term is not really used. Instead we talk about an object type.
An object is similar to a tuple, but it knows its type at runtime and we can decide which members we want to be visible outside the containing module. We can also inherit from an existing object type, single inheritance. Let’s hack some code:
# Distinct types seem useful for units, not essential
# for this sample code, but whatever, let's use them.
type
Dollar* = distinct float
Kg* = distinct float
# We can define $ for Dollars too
proc `$`*(x: Dollar) :string =
$x.float
# Let's borrow `==` for simpler code
proc `==`*(x, y: Dollar) :bool {.borrow.}
# Let's create a base class for fruits with country
# of origin and a price in dollar. Note that we typically
# inherit from RootObj which is basically like the Object
# class in both Smalltalk and Java.
# Also note that we declare Fruit to be a ref type.
type
Fruit* = ref object of RootObj
origin*: string
price*: Dollar
# We like to deal with different sizes of bananas
# so we create a subtype and add a size member.
type
Banana* = ref object of Fruit
size*: int
# And pumpkins can have very different weights
type
Pumpkin* = ref object of Fruit
weight*: Kg
# A very big one
BigPumpkin* = ref object of Pumpkin
# And... can we also make a non ref subtype of
# a ref subtype, seems so. The ref property itself is
# thus not inherited.
type
NonRefSubBanana = object of Banana
# Base reduction is just zero, override in subtypes.
# Made this a method to see if we can override it with a proc.
method reduction*(self) :Dollar =
Dollar(0)
# Override with a proc. Humpty dumpty, should bind statically
# for Bananas, otherwise call the one above.
proc reduction*(self: Banana) :Dollar =
Dollar(9)
# Our base implementation just makes sure we round off
# to nearest cent and subtracts any reduction.
import math
proc calcPriceProc*(self) :Dollar =
Dollar(round(self.price.float * 100)/100 - self.reduction().float)
# Lets implement it smarter for Pumpkins. Here we convert
# to a Fruit in order to call the "super" implementation.
proc calcPriceProc*(self: Pumpkin) :Dollar =
Dollar(calcPriceProc(Fruit(self)).float * self.weight.float)
# BigPumpkin - 1000 bucks! Take it or leave it!
# This is a method overriding the base proc
method calcPriceProc*(self: BigPumpkin) :Dollar =
Dollar(1000)
# A base implementation too, but as a method instead of a proc.
method calcPriceMethod*(self: Fruit) :Dollar =
Dollar(round(self.price.float * 100)/100 - self.reduction().float)
# And a method similarly for Pumpkins, hum...
# We can't use the type conversion "super call" technique - because methods
# dispatch on runtime type - so how can we call the method above???
# We can't, fall back on calling the base proc instead.
method calcPriceMethod*(self: Pumpkin) :Dollar =
Dollar(calcPriceProc(Fruit(self)).float * self.weight.float)
Phew! So the above little fruit library sets up some trivial inheritance and adds some procs and methods to these object types which we want to play with to see how the inheritance works. Now, the following code uses the above library:
import fruit
# Create some fruits, normally one would not use constructor
# syntax like this, instead call a proc in the fruit module
# that does it for us, encapsulation.
var p = Pumpkin(origin: "Africa", price: 10.00111.Dollar, weight: 5.2.Kg)
var b = Banana(origin: "Liberia", price: 20.00222.Dollar)
var bp = BigPumpkin(origin: "Africa", price: 10.Dollar, weight: 15.Kg)
# BigPumpkins have a method overriding the base proc, it works!
assert(bp.calcPriceProc() == 1000.Dollar)
# Works for Banana, uses Fruit base proc, we see it rounds to cents
# and it also then make a self call to reduction() for Bananas.
assert(b.calcPriceProc() == 11.0.Dollar)
# Works for Pumpkin, static binding. Rounds to cents (the super call)
# and multiplies with weight. No reduction, correct.
assert(p.calcPriceProc() == 52.0.Dollar)
# What happens in a proc generalized for Fruits? Type info is lost so
# static binding will bind to base implementation regardless of what x is.
proc testingProcs(x: Fruit) :Dollar =
# Here the type of x is Fruit
x.calcPriceProc()
# Lets call the above proc and see...
# Oops, the self send reduction() misses that its a Banana!
assert(testingProcs(b) == 20.Dollar) # Should be 11
# Oops, the override of calcPriceProc() for Pumpkins is also missed!
assert(testingProcs(p) == 10.0.Dollar) # Should be 52
# But with generics it works just fine... We can also constrain it to
# only accept Banana and Pumpkin.
proc testingProcsGeneric[T: Banana|Pumpkin](x: T) :Dollar =
# Here Nim will produce multiple variations of this method, for both Banana
# and Pumpkins (call sites below), so type information is not lost.
# It should call the correct proc.
x.calcPriceProc()
# All good with generics
assert(testingProcsGeneric(b) == 11.0.Dollar)
assert(testingProcsGeneric(p) == 52.0.Dollar)
# If we call a method the type of x doesn't matter, its the type of the object
# itself that counts.
proc testingMethods(x: Fruit) :Dollar =
# Here we will dispatch dynamically
x.calcPriceMethod()
# All good... or??? Oops, the reduction for Bananas is lost!
assert(testingMethods(b) == 20.0.Dollar) # Should be 11
# The override for Pumpkin works fine
assert(testingMethods(p) == 52.0.Dollar)
echo "All good, well, or at least we got what the comments said."
Did you follow all that? Really? Then explain it to me! :)
Basically, mixing procs and methods … is tricksy.
So let’s shorten, remove comments, regroup code into “classes” and only use methods. To solve the “super call” we throw in a template so that we can reuse that code in two different methods. Not the same, but ok:
import math
# Dollars and Kgs
type
Dollar* = distinct float
Kg* = distinct float
proc `$`*(x: Dollar) :string =
$x.float
proc `==`*(x, y: Dollar) :bool {.borrow.}
# Fruit class
type
Fruit* = ref object of RootObj
origin*: string
price*: Dollar
method reduction*(self: Fruit) :Dollar =
Dollar(0)
# Code broken out in a template for reuse, since super call doesn't
# fly with methods yet.
template basePrice(): Dollar =
Dollar(round(self.price.float * 100)/100 - self.reduction().float)
method calcPrice*(self: Fruit): Dollar =
# Use template, zero cost
basePrice()
# Banana class
type
Banana* = ref object of Fruit
size*: int
method reduction*(self: Banana): Dollar =
Dollar(9)
# Pumpkin
type
Pumpkin* = ref object of Fruit
weight*: Kg
method calcPrice*(self: Pumpkin) :Dollar =
# Use template, zero cost
Dollar(basePrice().float * self.weight.float)
# BigPumpkin
type
BigPumpkin* = ref object of Pumpkin
method calcPrice*(self: BigPumpkin) :Dollar =
Dollar(1000)
And the code testing it:
import fruit
var p = Pumpkin(origin: "Africa", price: 10.00111.Dollar, weight: 5.2.Kg)
var b = Banana(origin: "Liberia", price: 20.00222.Dollar)
var bp = BigPumpkin(origin: "Africa", price: 10.Dollar, weight: 15.Kg)
assert(bp.calcPrice() == 1000.Dollar)
assert(b.calcPrice() == 11.0.Dollar)
assert(p.calcPrice() == 52.0.Dollar)
# What happens in a proc generalized for Fruits? Type info is lost
# but since we now use only methods, it doesn't matter
proc testing(x: Fruit) :Dollar =
x.calcPrice()
assert(testing(b) == 11.Dollar)
assert(testing(p) == 52.0.Dollar)
assert(testing(bp) == 1000.Dollar)
echo "All good with only methods."
What I learned from the above:
- Single inheritance works fine in Nim, no surprises really. Sure, procs and methods are defined “on their own” but there is no practical difference.
- Procs bind statically and calling a “super” proc is easy using type conversion. But… if the super method calls other methods… ouch! Type info lost! Better to use templates or similar as above.
- If we don’t use generics but instead use base types (like Fruit) for arguments, we will “lose” type information, and potentially we “miss” calling our overrides! Not a surprise to a hardcore static guy, but… as a dynamic typing dude - this is a gotcha! Using methods only of course avoids that issue.
- Methods and procs can be mixed, but here there be dragons. I think.
- If we use methods we currently can’t call a “super” method. Workaround today is to factor out the base implementation, for example in a template, as done above. UPDATE: See part IV about this.
- If we use procs only and apply generics (I did but didn’t bother including that code), it works perfectly fine too in this example. But as noted, do not use type conversion to a base type to do super calls, unless you are sure what you are doing. :)
- If you have several classes like this in the same module, take care of the order of procs - make sure your overrides are defined before their uses. Otherwise you can easily end up calling a base implementation, just because the compiler hasn’t seen the override definition yet!
Remark Link to heading
Phew. In summary I would say the OO features are mostly there. Super calls (for both procs and methods I would say) is evidently a “hole” in the language, I think it needs some kind of solution. But coding and testing is a very nice experience, its not that hard to get into it. But I would say it will take some practice before you know what routes are available for OO in Nim.
Conclusion Link to heading
I have only begun discovering Nim so I have yet to see how OO works in a larger Nim codebase. I also haven’t really explored lambdas and several of the datatypes yet, nor macros and templates and lots of other things. But I feel confident that Nim can do OO code quite well.
Go Nim!